Joint Summarization of Large Sets of Web Images and Videos
People
Leonid Sigal (Disney Research)
Eric P. Xing (CMU)
Publication
Gunhee Kim, Leonid Sigal, and Eric P. Xing
Joint Summarization of Large-scale Collections of Web Images and Videos for Storyline Reconstruction
27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, Ohio, USA, Jun 23-28, 2014. (Acceptance = 540 / 1807 ~ 29.88 %)
[Paper (PDF)] [Presentation (PPTX)] [Poster (PDF)] [1min Video (MOV)]
Matlab code
We are working on a journal version. We will post the code after the Journal submission.
Description
Motivation of Research
The objective of this research is to jointly summarize large sets of online Flickr images and YouTube user videos. Since their characteristics are different yet complementary, using both media is mutually rewarding (i.e. help each other).
Let’s take a look at why collections of images help video summarization with an example of Fig.1.(a). One major issue of videos is that they often contain redundant and noisy information such as backlit subjects, motion blurs, overexposure, and full of trivial backgrounds like sky or water. However, usually pictures are more carefully taken so that they capture the subjects from canonical viewpoints in a more semantically meaningful way. Therefore, by using simple similarity votes from crowds of fly fishing images, we can get rid of such noisy, redundant, or semantically meaningless parts of videos.
In the reverse direction, collections of videos help story-based image summarization (See Fig.1.(b)). Here’s an example of Flickr photo stream. One issue of still images is that they are fragmentally recorded, so the sequential structure is often missing even between consecutive images in a single photo stream. However, videos are motion pictures, which convey temporal smoothness between frames. Therefore, we leverage sets of videos to discover underlying sequential structure as a coherent thread of storyline.
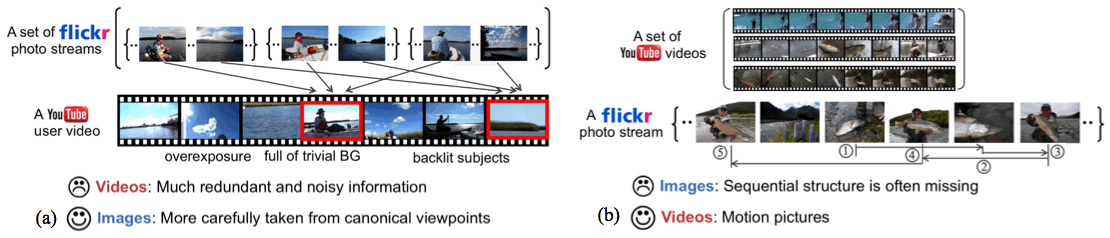 Figure 1. Benefits of jointly summarizing Flickr images and YouTube videos illustrated on a fly+fishing activity. (a) Typical user videos contain noisy and redundant information, which can be removed using similarity votes cast by a large set of images that are taken more carefully from canonical viewpoints. The frames within red boxes are selected as video summary using our method.(b) Although images in a photo stream are taken consecutively, the underlying sequential structure between images is missing, which can be discovered with the help of a collection of videos. |
Method and Experiments
The video summarization is achieved by diversity ranking on the similarity graphs between images and video frames. The storyline graphs is created by the inference of sparse time-varying directed graphs from a set of photo streams with assistance of videos.
For evaluation, we collect the datasets of 20 outdoor activities, consisting of 2.7 millions Flickr images and 16 thousands YouTube videos. We evaluate our algorithm via crowdsourcing using Amazon Mechanical Turk. In our experiments, we demonstrate that the proposed joint summarization approach outperforms other baselines and our own methods using videos or images only.
Funding
This research is supported by Disney Research.