Unsupervised Detection of Regions of Interest Using Iterative Link Analysis
People
Publication
Gunhee Kim and Antonio Torralba
Unsupervised Detection of Regions of Interest using Iterative Link Analysis Annual Conference on Neural Information Processing Systems (NIPS 2009), Vancouver, Canada, December 7-10, 2009. (Acceptance = 263/1105~23.8%)
[Paper(PDF)] [Presentation(PPT)] [Poster(PPT)]
Description
This paper proposes a fast and scalable alternating optimization technique to detect regions of interest (ROIs) in cluttered Web images without labels. Fig. 1 shows the problem statement. The input is a large-scale image set without any labels. It may consist of a single object type or multiple object types. The goal is to detect regions of interests in each image of the dataset. We define the ROI as a highly probable rectangular region of an object instance.
 Figure 1. Problem statement. (The yellow boxes are groundtruthsand red and blue ones are the ROIs detected by our method). |
Our algorithm is based on the alternating optimization idea. Alternating optimization is one of widely used heuristics where optimization over two sets of variables is not straightforward, but optimization with respect to one while keeping the other fixed is much easier and solvable. The basic idea is that the unsupervised ROI detection can be thought of a chicken-and-egg problem between (1) exemplar finding and (2) ROI refinement. (See Fig. 2.) If class representative exemplars are given, the detection of objects in images is solvable (i.e. a conventional detection or localization problem). Conversely, if object instances are clearly annotated beforehand, the exemplars can be easily obtained (i.e. a conventional modeling or ranking problem).
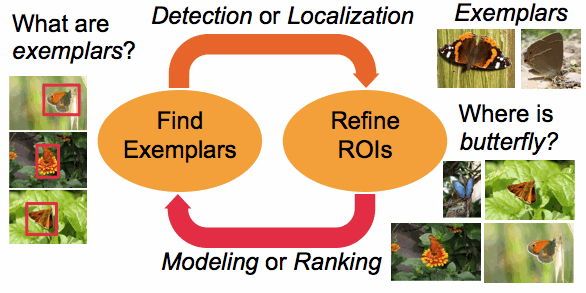 Figure 2. Basic idea of our approach - Alternating optimization. |
Fig.3 summarizes the proposed algorithm. The input is a set of images and a set of ROI hypotheses for all images. And the output should be the selection of more than one ROI hypotheses in each image. Initially, we assume that the image itself is the best ROI of each image. It turned out that this initialization is reasonable enough for Web images. Then we generate a similarity network between them, and apply the proposed hub seeking subfunction to the network to obtain small sets of hub images using two criteria - centrality and diversity. In the next ROI refinement subfunction, we generate a bipartite graph between the initial hub set and all possible ROIs in each image. If we apply a ranking algorithm like a PageRank, then the ranked scores of these ROI candidates indicate relative importance with respect to the hub set. Simply, the ROI hypothesis with maximum ranked score would be the refined best ROI of the image at this particular time step. The better ROI selection is likely to lead the better hub set in the next iteration. If we iterate these two processes, hopefully we can come up with the best bounding box annotation in each image of the dataset.
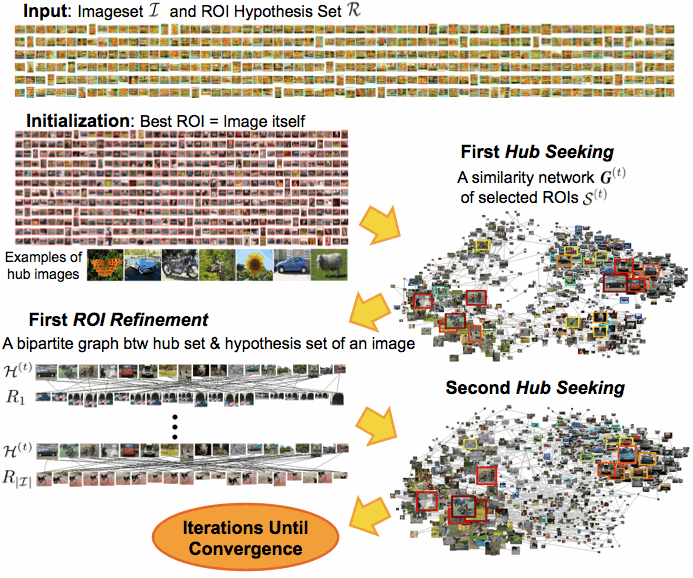 Figure 3. Algorithm. |
Fig. 4 shows some localization examples. The first two rows are examples of success, and the third row illustrates some typical examples of mismatches with ground-truths. Frequently co-occurred objects can be detected instead such as flowers in butterfly images, insects on sunflowers, other animals in the zoo, and persons everywhere. Sometimes small multiple instances are detected by a single ROI or a part of an object is discovered (e.g. a giraffe face rather than its whole body). Other quantitative results are described in the paper.
 Figure 4. Localization results. (The yellow boxes are groundtruthsand red and blue ones are the ROIs detected by our method). |
Funding
NSF Career award (IIS 0747120). (This research was done while Gunhee Kim was visiting MIT).