Unsuperised Modeling and Recognition of Object Categories
People
Publication
Gunhee Kim, Christos Faloutsos, and Martial Hebert
Unsupervised Modeling and Recognition of Object Categories with Combination of Visual Contents and Geometric Similarity Links ACM International Conference on Multimedia Information Retrieval (ACM MIR 2008), Vancouver, Canada, October 30-31, 2008. (Oral) (Acceptance = 20/264 ~ 7.6%)
[Paper(PDF)] [Presentation(PPT)]
Description
This paper proposes a probabilistic approach to unsupervised modeling and recognition of object categories that combines two types of complementary visual evidence - visual features of the images and inter-connected similarity links between them. By doing so, our approach not only increases modeling and recognition performance but also provides possible solutions to several problems including modeling of geometric information, computational complexity, and the inherent ambiguity of visual words.
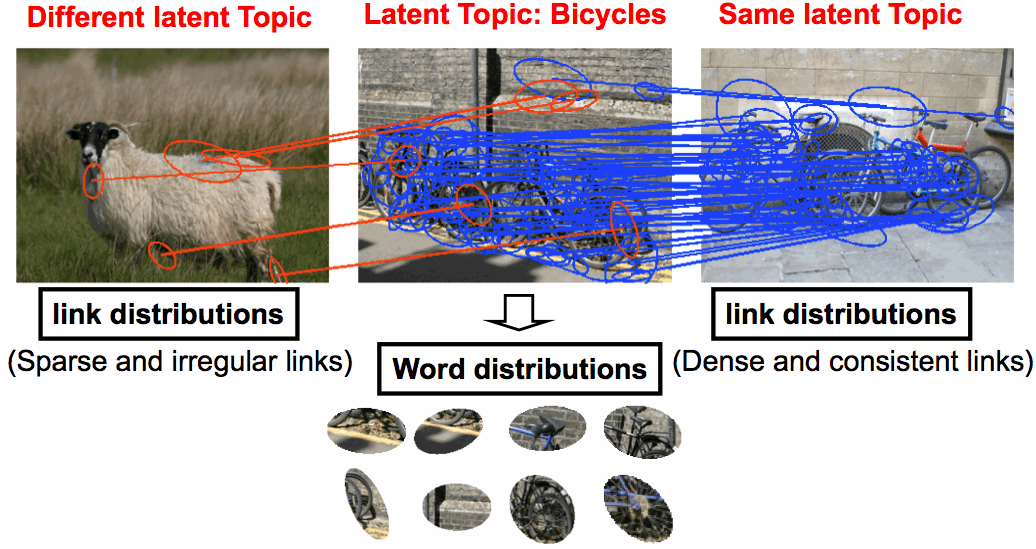 Figure 1. Intuition of the proposed approach. |
The basic idea is simple. Fig. 1 illustrates the intuition of our approach. The conventional topic models in computer vision are based on the samples of visual words that are generated from a mixture model of latent topics (e.g., object classes). Our major extension is that if we have a sufficiently reasonable image matching algorithm, the distributions of the links generated by the matcher are highly likely to be governed by the same latent topics as well. In other words, if two images share similar latent topics (e.g., two bicycle images in Fig. 1), then the matcher should generate a large number of consistent correspondences between features in the pair of images. Otherwise, the correspondences between the images may be sparse and irregular e.g., the pair of the sheep and bicycle images in Fig. 1).
This paper considers two standard topic models in computer vision such as pLSA and LDA although, in principle, there is no limitation to integration with any generative models. The link analysis techniques are very popular in other research areas such as text analysis, web applications, and bioinformatics. Therefore, the pLSA and LDA based models which combine topic contents with link analysis have been used in other research communities 5. The statistical models that we used are based on this earlier work.
Fig. 2 shows some localization examples on the MSRC and PASCAL05 datasets. We draw the features by different colors according to the assigned topics. As shown in the pictures, the majority of topics assigned to high confident features are consistent with the main topic of the image.
  Figure 2. Examples of localization. |
Funding
Intelligent Robotics Development Program, a 21st Century Frontier R&D Programs by the Ministry of Commerce, Industry, and Energy of Korea.