Visualizing Brand Associations from Web Community Photos
Papers are now available.
People
Eric P. Xing (CMU)
Publication
Gunhee Kim and Eric P. Xing
Visualizing Brand Associations from Web Community Photos,
ACM International Conference on Web Search and Data Mining (WSDM 2014), New York City, USA, February 24-28, 2014. (Acceptance = 64/356 ~ 18.0%)
[Paper (PDF)] [Presentation (PPTX)] [Poster (PDF)]
Gunhee Kim and Eric P. Xing
Discovering Pictorial Brand Associations from Large-Scale Online Image Data
IEEE Workshop on Large Scale Visual Commerce (LSVisCom) in conjunction with (ICCV 2013), Sydney, Australia, December 1-8. (Best Paper Award)
[Paper (PDF)]
Press Release
![]()
![]()
![]()
![]()
![]()
Matlab example code
Will be updated soon.
Description
Motivation of Research
Brand Associations, one of central concepts in marketing, describe customers’ top-of-mind attitudes or feelings toward a brand. Thus, this consumer-driven brand equity often attains the grounds for purchasing products or services of the brand. Traditionally, brand associations are measured by analyzing the text data from consumers’ responses to the survey or their online conversation logs. In this paper, we propose to go beyond text data and leverage large-scale online photo collections contributed by the general public.
Our underlying rational is if someone takes a picture and tags it as burger king, we regard the picture as his pictorial opinion on burger king. If we crawl millions of such images, we safely assume that we can read the general public’s pictorial opinions toward the burger king.
As a first technical step toward picture-based brand association study, we address the problem of jointly achieving the two-levels of visualization tasks. First one is image-level task to detect and visualize key concepts associated with brands. More specifically, we first identify a small number of exemplars and image clusters, and project them in a circular layout. More strongly associated clusters with the brand appear closer to the center of the map, and more similar pairs of clusters have smaller angular distances. The second task is subimage-level one, in which we localize the regions that are most associated with the brand in each image in an unsupervised way.
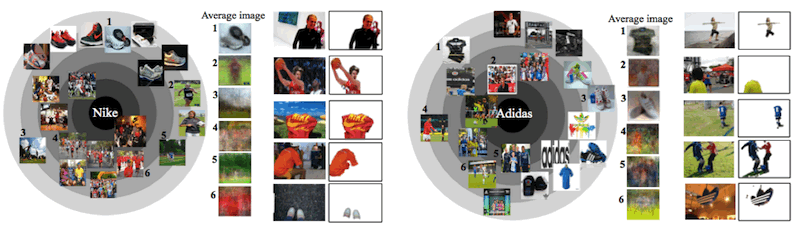 Figure 1. Two visualization tasks for the brand associations leveraging Web community photos (e.g. Nike and Adidas). |
Method
For each brand, we first build a K-nearest neighbor similarity graph between images. Then,we perform exemplar detection, whose goal is to find out a small set of representative images called exemplars. We use the diversity ranking algorithm of our previous work. Next, we localize the regions that are most relevant to the brand in each image. We formulate the brand localization as the problem of cosegmentation; we apply the MFC algorithm to the images of each cluster in order to simultaneously segment out recurring objects or foregrounds across the multiple images.
Take-home Message
We proposed a scalable approach to jointly aligning and segmenting multiple uncalibrated Web photo streams of different users in an unsupervised and bottom-up way. The empirical results assured that our method can be a key component to achieve our ultimate goal: inferring collective photo storylines from Web images, which is a next direction of our future work.
Funding
This research is supported by NSF IIS-1115313, AFOSR FA9550010247, Google, and Alfred P. Sloan Foundation.